双调排序是并行计算里面一个非常重要而且常见的应用。其思想跟归并排序一样,都是用了分治的思想。
为什么它叫做双调排序呢?因为Bitonic Sort 会先将一个数列排序成为前半段单调递增,后半段单调递减
的这么一个序列(中间过渡使用),这样一个前半段单调递增,后半段单调递减的序列,我们又把它叫做Bitonic sequence(双调序列)。
具体实现Bitonic Sort的操作如下:
下图所示是一个Bitonic Sort的示意图:
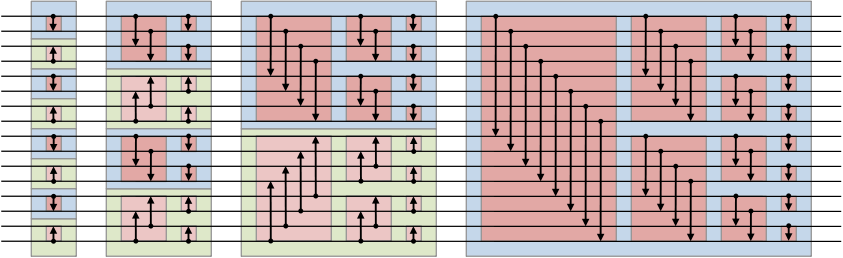
- 先将任意序列变为双调序列。
假设有一个长为n的序列,n = 2 ^ k,那么,我们将其两两分组,假设n = 16,如下图所示,为了便于理解,我们假设数组从nums[1] 到nums[16](这一点跟C/C++/Python 数组的起始index不同,只是为了方便)
我们先进行第一步,那么一共有8组,所有奇数组的数字,比如 nums[1] 和 nums[2](第一组), 又或者 nums[5] 和nums[6](第三组)等等,进行两两比较,比较的结果是,小的在前,大的在后。
1 | if nums[1] > nums[2]: |
同理,所有偶数组的数字,比如nums[3] 和 nums[4],他们比较的结果相反,大的在上,小的在下。如此一来,nums[1], nums[2], nums[3],nums[4] 这4个数字就形成了一个bitonic sequence。
第二步,此时,我们将前面一步的8组结果,进行两两合并,成为4组数据,每一组里面呢,第一个数字跟第三个数字比较,第二个数字跟第四个数字比。如果是奇数组,那么依然是大的放到后面,小的数字放到前面。偶数组,大的在前,小的在后。
这样还不算完,第二步分成了两个部分,比较完了,nums[1]和nums[3],nums[2]和nums[4],我们还需要将nums[1]和nums[2],nums[3]和nums[4] 再次进行小组比较。如此一来,第一组(nums[1],nums[2],nums[3],nums[4]就成为了一个生序序列,而第二组成为了一个降序序列。
第三步,与前一步雷同,需要将4组数据进行两两合并,此时只有两个大组。
第四步,与前一步依然雷同,只是由于只有一组数据了,我们所做的,就是将一大组bitonic sequence进行梳理,整理成为一个升序序列。
Bitonic sort 的Python实现:
1 | def bitonic_sort(up: bool, x: Sequence[int]) -> List[int]: |
那么,Bitonic Sort 的时间复杂度和空间复杂度分别都是什么样的呢?
假设S(n)是sort n个数字所需要的比较的次数,M(n)是合并n个数字所需要的比较的次数。
那么我们有,S(n) = 2*S(n) + M(n), M(n) = 2 * M(n) + n / 2,解出来可以得到
M(n) = O(nlog(n))
S(n) = O(n(log(n))^2)
粗一看,时间比merge sort或者quick sort还要慢,但是我们必须要搞明白,我们可以create n个thread
这样时间复杂度就只有O((log(n))^2) 了。
因为总共需要O(n(log(n))^2)次比较,每次比较都需要新开内存,所以space complexity是O(n(log(n))^2)。
如果大家感兴趣的,也可以看一看bitonic sort 在cuda里的实现,上述代码只是简单的讲一下bitonic实现的原理,
但是实际上并不会比merge sort或者quick sort更快,因为我们既没有用到多线程,也没有使用GPU。
CUDA 实现Bitnoic Sort: https://gist.github.com/mre/1392067
MPI 实现Bitnoic Sort: https://github.com/orestisfl/mpi_bitonic_sort