The Hungarian method is a combinatorial optimization algorithm that solves the assignment problem in polynomial time and which anticipated later primal-dual methods. Why we bring it up here today? It is a widely used algorithm in data point association which means it can be also used in autonomous driving for multi-target tracking.
In order to have a good understanding in Hungarian Algorithm, we will have to first understand a few concepts:
Bipartite graph
A bipartite graph (or bigraph) is a graph whose vertices can be divided into two disjoint and independent sets U and V such that every edge connects a vertex in U to one in V. Let us take a look at a example as below:
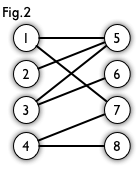
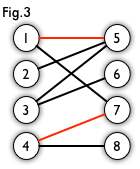
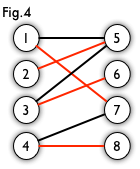
Let`s take a look at Fig. 1. This is a bipartite graph.
match
A vertex is matched (or saturated) if it is an endpoint of one of the edges in the matching. Otherwise the vertex is unmatched.
Maximal matching
A maximal matching is a matching M of a graph G that is not a subset of any other matching.
Maximum matching
In graph theory, a maximum matching is a matching that contains the largest possible number of edges.
Perfect matching
If one matching in all the matching of a graph, can make all the vertices matched, then we call this matching a perfect matching. It is very commonly seen that a graph does not have any perfect matching.
Alternating Path
It is a path that begins with an unmatched vertex and[2] whose edges belong alternately to the matching and not to the matching.
Augmenting Path
It is an alternating path that starts from and ends on free (unmatched) vertices.
From Fig 5, we have a augmenting path like Fig 6.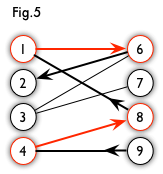
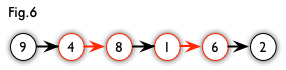
Algorithm details
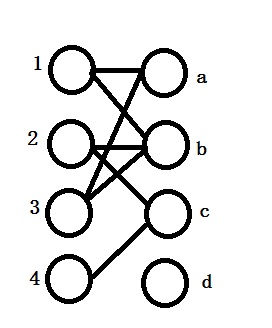
Let us take an example:
We are trying to match the vertices 1,2,3,4 with a,b,c,d. The relationship between vertices is shown as below:
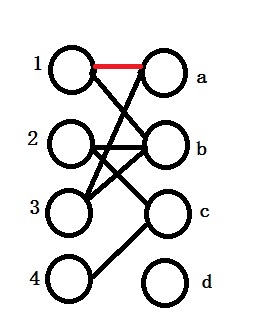
We first assign 1 to a, we mark it as red indicate that it is a match.
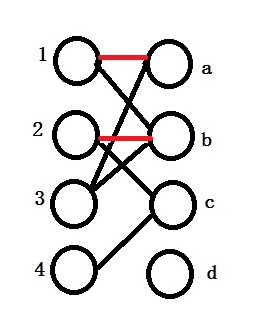
Then we match 2 with b.
We are trying to match 3 a vertice however we find that a and b both are matched with other vertices. So we are trying to reassign 1 to another vertice. We mark it as blue.
<img src=”/images/Hungarian_Algorithm/example4.jpeg” “>
Similarly, we find that we cannot assign 1 to another vertice because b is occupied too. We have to unassign b to 2 and assign b to 2. We get c for 2 instead.
<img src=”/images/Hungarian_Algorithm/example5.jpeg” “>
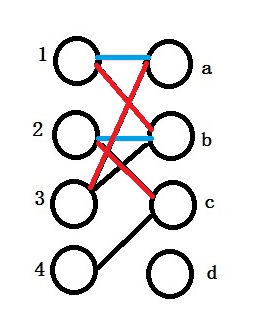
Now 1 gets b which is marked as red. Similarly 2 gets c, 3 gets a.
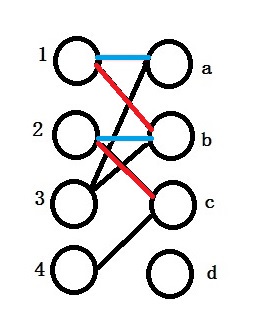
As for 4, because c is assigned, and we cannot asssign other vertices for 1, 2, 3. It reaches the end of the algorithm. The main idea is to reassign some vertices to others and see if it can increase the totally number of matchings.
Hungarian Tree
A hungarian tree usually got generated by BFS. we start from a
unmatched vertex, and traverse the graph though alternating path until it cannot be extended. Let us take a look at an example.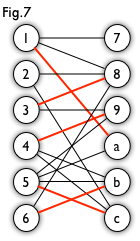
From Fig7, we can generate a BFS tree like Fig8.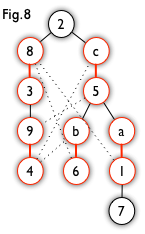
For a graph like the left one in Fig9, we can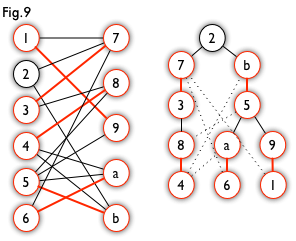
Algorithm implementation.
See the source code as below:
1 | struct Edge |