The Hungarian method is a combinatorial optimization algorithm that solves the assignment problem in polynomial time and which anticipated later primal-dual methods. Why we bring it up here today? It is a widely used algorithm in data point association which means it can be also used in autonomous driving for multi-target tracking.
In order to have a good understanding in Hungarian Algorithm, we will have to first understand a few concepts:
Bipartite graph
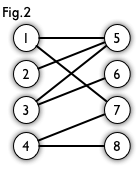
A bipartite graph (or bigraph) is a graph whose vertices can be divided into two disjoint and independent sets U and V such that every edge connects a vertex in U to one in V. Let us take a look at a example as below: Let`s take a look at Fig. 1. This is a bipartite graph.
match
A vertex is matched (or saturated) if it is an endpoint of one of the edges in the matching. Otherwise the vertex is unmatched.
Maximal matching
A maximal matching is a matching M of a graph G that is not a subset of any other matching.
Maximum matching
In graph theory, a maximum matching is a matching that contains the largest possible number of edges.
Perfect matching
If one matching in all the matching of a graph, can make all the vertices matched, then we call this matching a perfect matching. It is very commonly seen that a graph does not have any perfect matching.
Alternating Path
It is a path that begins with an unmatched vertex and[2] whose edges belong alternately to the matching and not to the matching.
Augmenting Path
It is an alternating path that starts from and ends on free (unmatched) vertices.
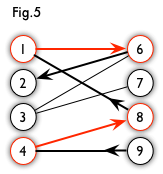
From Fig 5, we have a augmenting path like Fig 6.
Algorithm details
Let us take an example:
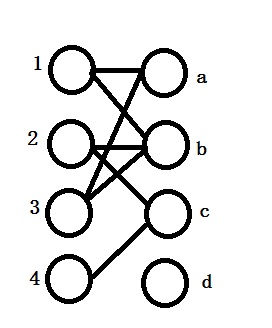
We are trying to match the vertices 1,2,3,4 with a,b,c,d. The relationship between vertices is shown as below:
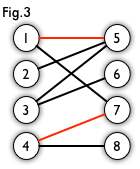
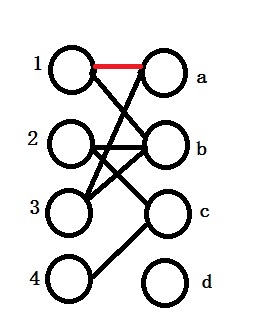
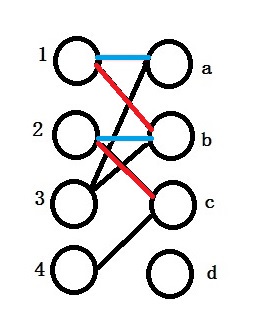
We first assign 1 to a, we mark it as red indicate that it is a match.
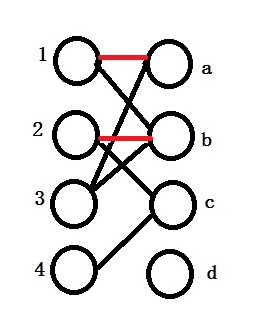
Then we match 2 with b.
We are trying to match 3 a vertice however we find that a and b both are matched with other vertices. So we are trying to reassign 1 to another vertice. We mark it as blue.
Similarly, we find that we cannot assign 1 to another vertice because b is occupied too. We have to unassign b to 2 and assign b to 2. We get c for 2 instead.
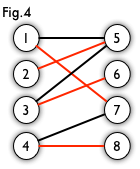
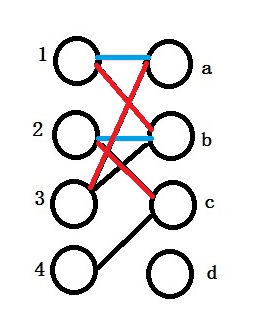
Now 1 gets b which is marked as red. Similarly 2 gets c, 3 gets a.
As for 4, because c is assigned, and we cannot asssign other vertices for 1, 2, 3. It reaches the end of the algorithm. The main idea is to reassign some vertices to others and see if it can increase the totally number of matchings.
Hungarian Tree
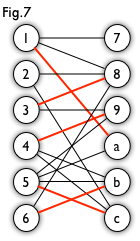
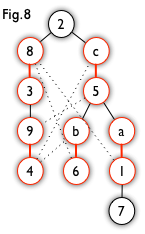
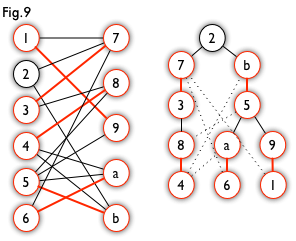
A hungarian tree usually got generated by BFS. we start from a unmatched vertex, and traverse the graph though alternating path until it cannot be extended. Let us take a look at an example. From Fig7, we can generate a BFS tree like Fig8. For a graph like the left one in Fig9, we can
Edge(int f, int t, int w):from(f), to(t), weight(w) {} };
vector<int> G[__maxNodes]; /* G[i] 存储顶点 i 出发的边的编号 */ vector<Edge> edges; typedef vector<int>::iterator iterator_t; int num_nodes; int num_left; int num_right; int num_edges;
int matching[__maxNodes]; /* 存储求解结果 */ int check[__maxNodes];
bool dfs(int u) { for (iterator_t i = G[u].begin(); i != G[u].end(); ++i) { // 对 u 的每个邻接点 int v = edges[*i].to; if (!check[v]) { // 要求不在交替路中 check[v] = true; // 放入交替路 if (matching[v] == -1 || dfs(matching[v])) { // 如果是未盖点,说明交替路为增广路,则交换路径,并返回成功 matching[v] = u; matching[u] = v; return true; } } } return false; // 不存在增广路,返回失败 }
int hungarian() { int ans = 0; memset(matching, -1, sizeof(matching)); for (int u=0; u < num_left; ++u) { if (matching[u] == -1) { memset(check, 0, sizeof(check)); if (dfs(u)) ++ans; } } return ans; }
queue<int> Q; int prev[__maxNodes]; int Hungarian() { int ans = 0; memset(matching, -1, sizeof(matching)); memset(check, -1, sizeof(check)); for (int i=0; i<num_left; ++i) { if (matching[i] == -1) { while (!Q.empty()) Q.pop(); Q.push(i); prev[i] = -1; // 设 i 为路径起点 bool flag = false; // 尚未找到增广路 while (!Q.empty() && !flag) { int u = Q.front(); for (iterator_t ix = G[u].begin(); ix != G[u].end() && !flag; ++ix) { int v = edges[*ix].to; if (check[v] != i) { check[v] = i; Q.push(matching[v]); if (matching[v] >= 0) { // 此点为匹配点 prev[matching[v]] = u; } else { // 找到未匹配点,交替路变为增广路 flag = true; int d=u, e=v; while (d != -1) { int t = matching[d]; matching[d] = e; matching[e] = d; d = prev[d]; e = t; } } } } Q.pop(); } if (matching[i] != -1) ++ans; } } return ans; }
A radar tracker is a component of a radar system, or an associated command and control (C2) system, that associates consecutive radar observations of the same target into tracks. It is particularly useful when the radar system is reporting data from several different targets or when it is necessary to combine the data from several different radars or other sensors.
A classical rotating air surveillance radar system detects target echoes against a background of noise. It reports these detections (known as “plots”) in polar coordinates representing the range and bearing of the target. In addition, noise in the radar receiver will occasionally exceed the detection threshold of the radar’s Constant false alarm rate detector and be incorrectly reported as targets (known as false alarms). The role of the radar tracker is to monitor consecutive updates from the radar system (which typically occur once every few seconds, as the antenna rotates) and to determine those sequences of plots belonging to the same target, whilst rejecting any plots believed to be false alarms. In addition, the radar tracker is able to use the sequence of plots to estimate the current speed and heading of the target. When several targets are present, the radar tracker aims to provide one track for each target, with the track history often being used to indicate where the target has come from.
A radar track will typically contain the following information:
Position (in two or three dimensions)
Heading
Speed
Unique track number
status
Age – used in tracker initiation and maintenance
I would believe in the future, when 4D radar becomes popular, category of the object will definitely become an importannt information which can be provided by radar. They just the dense radar point cloud to train the neural network to classify the object type. Currently, the automotive radar only provides a parse reflection data point instead of a point cloud.
How to implement radar tracker
1. Plot to track association: Associate a radar plot with an existing track
2. Track smoothing: Update the track with this latest plot
3. Track initiation: Spawn new tracks with any plots that are not associated with existing tracks
4. Track maintenance: Delete any tracks that have not been updated, or predict their new location based on the previous heading and speed
Track association
Perhaps the most important step is the updating of tracks with new plots. All trackers will implicitly or explicitly take account of a number of factors during this stage, including:
a model for how the radar measurements are related to the target coordinates
the errors on the radar measurements
a model of the target movement
errors in the model of the target movement
When I got the time, I will post an article to update all the information above.
we can first take a very light sip on the first topic – how the radar measurements are related to the target coordinates. A very famous clustering method in machine learning area – Kmeans clustering.
K means clustering
What is K means clustering ? It is an unsupervised machine learning method used for clustering. It aims to partition n observations into k clusters in which each observation belongs to the cluster with the centroid. So the process of radar data point association is an X-means clustering. The reason I used X here is because we don`t know how many clusters will be there finally. But for K means clustering, we have to first define that there will be and only will be K clusters.
Here are the steps for k means clustering.
Randomly generate k data points as centroids, these k data points must be within the range of the whole data set.
Pick a data point from the data set, calculate the Euclidean distance between the data point and all the centroids, assign the data point to the one with the smallest Euclidean distance.
Repeat step 2 for all the data points.
We will get k clusters now, recalculate the centroids. Repeat step 2 and step 3.
When the current centroids and previous centroids are close enough, end the process.
def kMeans(data,k=2): def _distance(p1,p2): """ In order to speed up, actually we don`t necessarily to use Euclidean distance, we just get the square of Euclidean distance will be good enough, it can save a lot of computing power. """ return np.sum((p1-p2)**2)
def get_centroid(data,k): """Generate k center within the range of data set.""" n = data.shape[1] # features centroids = np.zeros((k,n)) # init with (0,0).... for i in range(n): dmin, dmax = np.min(data[:,i]), np.max(data[:,i]) centroids[:,i] = dmin + (dmax - dmin) * np.random.rand(k) return centroids def is_converged(centroid1, centroids): set1 = set([tuple(c) for c in centroid1]) set2 = set([tuple(c) for c in centroid2]) return (set1 == set2) n = data.shape[0] # number of entries centroids = _rand_center(data,k) label = np.zeros(n,dtype=np.int) # track the nearest centroid assement = np.zeros(n) # for the assement of our model converged = False while not converged: old_centroids = np.copy(centroids) for i in range(n): # determine the nearest centroid and track it with label min_dist, min_index = np.inf, -1 for j in range(k): dist = _distance(data[i],centroids[j]) if dist < min_dist: min_dist, min_index = dist, j label[i] = j assement[i] = _distance(data[i],centroids[label[i]])**2 # update centroid for m in range(k): centroids[m] = np.mean(data[label==m],axis=0) converged = is_converged(old_centroids,centroids) return centroids, label, np.sum(assement)
An obvious weakness of K means clustering is that it could converge to local optimal instead of global optimal. So we could run the algorithm multiple times in order to get a better result.
Tracking smoothing:
Alpha-beta tracker
Kalman filter
Multiple hypothesis tracker(MHT)
Interacting multiple model
We will talk more about Kalman filter and Multiple hypothesis tracker in the future. Because these two are widely used in the industry.
Tracking initiation:
Track initiation is the process of creating a new radar track from unassociated radar plots. When the radar tracker is first switched on, all of the initial radar plots are used to initialize new tracks. Once the radar tracker is running, only those plots are used to create a new track that couldn’t be used to update an existing one.
Typically a new track is given the status of tentative until plots from subsequent radar updates have been successfully associated with the new track. Tentative tracks are not shown to the operator and so they provide a means of preventing false tracks from appearing on the screen – at the expense of some delay in the first reporting of a track.
Once several updates have been received, the track is confirmed and displayed to the operator. The most common criterion for promoting a tentative track to a confirmed track is the “M-of-N rule”, which states that during the last N radar updates, at least M plots must have been associated with the tentative track – with M=3 and N=5 being typical values. More sophisticated approaches may use a statistical approach in which a track becomes confirmed when, for instance, its covariance matrix falls to a given size.
A clutter map may be used to prevent track initiation in areas of strong clutter echoes not suppressed by the Doppler processing. The clutter map may also keep track of large bird echoes, so as to not be reinitiating track on them, repeatedly. Track initiation in a dense clutter environment can be quite demanding on computer software and hardware resources.
Tracker maintenance:
Track maintenance is the process in which a decision is made about whether to end the life of a track. If a track was not associated with a plot during the plot to track association phase, then there is a chance that the target may no longer exist (for instance, an aircraft may have landed or flown out of radar cover).
Alternatively, however, there is a chance that the radar may have just failed to see the target at that update, but will find it again on the next update. Common approaches to deciding on whether to terminate a track include:
If the target was not seen for the past M consecutive update opportunities (typically M=3 or so)
If the target was not seen for the past M out of N most recent update opportunities
If the target’s track uncertainty (covariance matrix) has grown beyond a certain threshold.
A list of techniques used in combination to improve a variety of computer vision task Object detection is, no doubt, one of the most fundamental applications in computer vision. Latest state-of-the-art detectors (including single-stage like YOLO or multiple-stage like RCNN [and derivatives]) are based on image classification backbone networks e.g., VGG, ResNet etc. There are multiple techniques “collectively known as Bag of Freebies”, which can be used in combination to boost the performance of all popular object detection networks without introducing extra computational cost during inference. Why Bag of Freebies got attention? Usually, object detectors are trained offline. Therefore, researchers always like to take advantage and develop better training methods which can make the object detector receive better accuracy without increasing inference cost. These methods only changes the training strategy or what we can say training cost. You can think bag of freebies as a pipeline of data augmentation techniques. The sole purpose of data augmentation is to increase the variability of the input images, so that the designed object detection model has higher robustness to the images obtained from different environments. In general, photometric distortions and geometric distortions are two commonly used data augmentation method and they definitely benefit the object detection tasks. In photometric distortions, we adjust the brightness, contrast, hue, saturation and noise of an image. For geometric distortions, we add random scaling, cropping, flipping, and rotating. In addition, some researchers engaged in data augmentation put their emphasis on simulating object occlusion issues (when an object covers a portion of another object.). These freebies are all training time modifications, and therefore, only affect model weights without changing the network structure and have achieved good results in image classification and object detection methods. Bag of Freebies In this section, we enlist an image mix-up method for object detection. We will introduce data processing and training schedule designed to improve performance of object detection models.
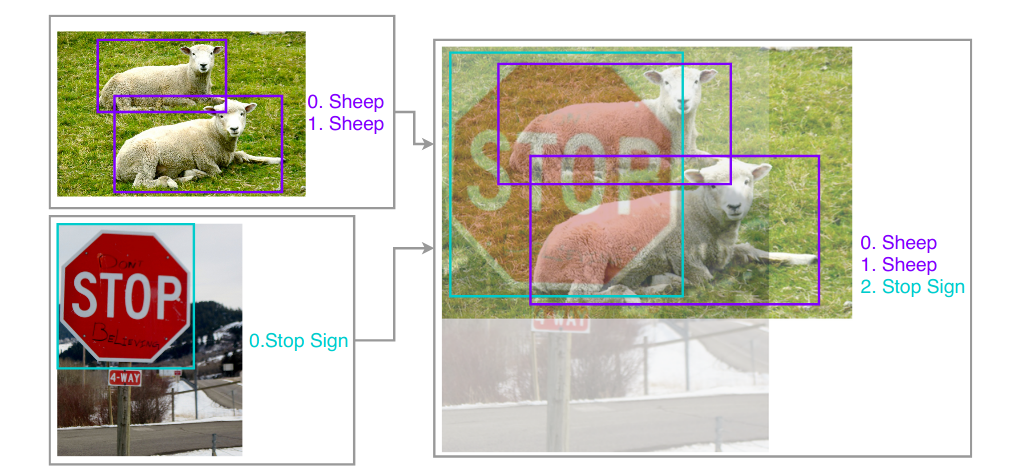
1. Image Mix-up for Object Detection
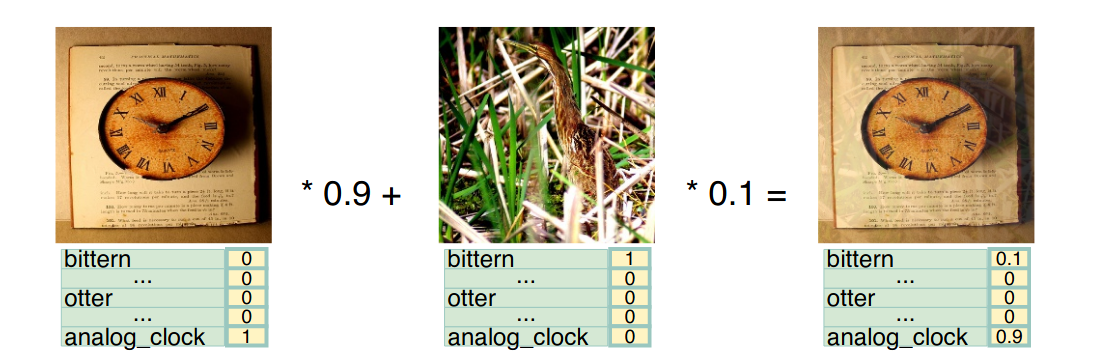
The key idea of mix-up in image classification task is to linearly mixing up pixels from one image to another image in a specific ratio where both images belong to the same training dataset. At the same time, one-hot encoded labels of both images are also mixed using the same ratio. The ratio in mix-up algorithm is drawn from a distribution called beta distribution written as B(alpha, beta). //small Mix-up visualization of image classification with typical mix-up ratio of 0.1: 0.9. Two images are mixed uniformly across all pixels, and image labels are weighted summation of original one-hot label vector. In this example, a bird image is mixed with a wall clock image in a typical 0.1: 0.9 ratio and so as their one-hot encoded labels. //small Geometry preserved alignment of mixed images for object detection. Image pixels are mixed up, object labels are merged as a new array. In this example, both images are merged along with their ground truth object coordinates as a new array while preserving their geometry. To verify mix-up designed for object detection, while choosing a beta distribution with alpha, beta are both at least 1,we experimentally test mix-up ratio distributions using the YOLOv3 network on Pascal VOC dataset. Below Table shows the actual improvements by adopting detection mix-up ratios sampled by different beta distributions. Beta distribution with alpha and beta both equal to 1.5 is marginally better than 1.0 equivalent to uniform distribution). It increases the mean average precision by almost 3% from the baseline. //small Effect of various mix-up approaches, validated with YOLO3 on Pascal VOC 2007 test set. Weighted loss indicates the overall loss is the summation of multiple objects with ratio 0 to 1 according to image blending ratio they belong to in the original training images. In contrast, Rosenfeld conducted a series of experiments name as “Elephant in the room”, where an elephant image patch is randomly placed on a natural image, then this adversarial image is used to challenge existing object detection models. The results indicate that existing object detection models are prune to such attack and show weakness to detect such transplanted objects. Researchers followed the same experiments by sliding an elephant image patch through an indoor room image, trained two YOLOv3 models on COCO 2017 dataset with one mix-up approach and other isn’t. They can observe that vanilla model trained without mix-up approach is struggling to detect “elephant in the room” due to heavy occlusion and lack of context because it’s rare to capture an elephant in a kitchen, and model trained with mix approach is more robust. In addition, they also noticed that mix model is more humble. less confident and generates lower scores for object on average. However, this behavior does not affect evaluation results as shown. //small Elephant in the room example. Model trained with geometry preserved mixup (bottom) is more robust against alien objects compared to baseline (top) It was obvious that model trained with visually coherent mixup is more robust (94.12 vs 42.95) to detect elephant in indoor scene even though it is very rare in natural images. And even mix-up model easily handles occlusion as you can see in bottom row. The mix-up model receives more challenges during training therefore is significantly better than vanilla model in handling unprecedented scenes and very crowded object groups. /small Statistics of detection results affected by elephant in the room. ”Recall of elephant” is the recall of sliding elephant in all generated frames, indicating how robust the model handles objects in unseen context.
2. Classification Head Label Smoothing
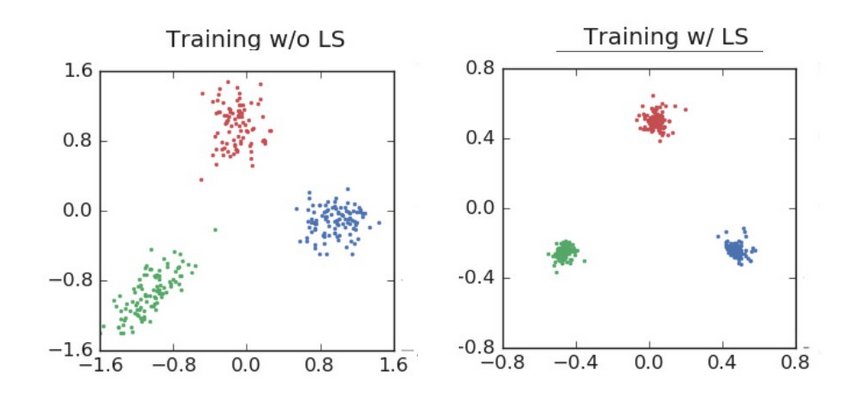
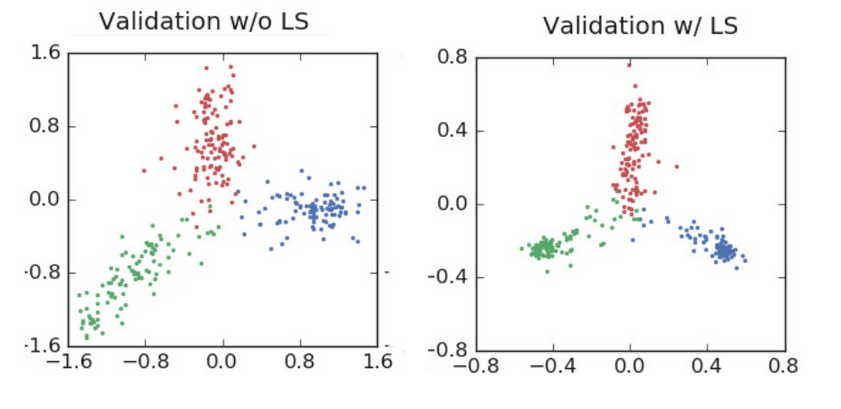
Label smoothing is a loss function modification that has been shown to be very effective for training deep learning networks. Label smoothing improves accuracy in image classification, translation, and even speech recognition. The simple explanation of how it works is that it changes the training target for the neural nets from a hard ‘1’ to ‘1-label smoothing adjustment’, meaning the neural nets is trained to be a bit less confident of it’s answers. Example: assume we want to classify images into dogs and cats. If we see a photo of a dog, we train the neural nets (via cross entropy loss) to move towards a 1 for dog, and 0 for cat. And if a cat, the reverse where we train towards 1 for cat, 0 for dog. In other words, a binary or “hard’ answer. However, neural nets have a bad habit of becoming ‘over-confident’ in their predictions during training, and this can reduce their ability to generalize and thus perform as well on new, unseen future data. In addition, large datasets can often include incorrectly labeled data, meaning inherently the neural nets should be a bit skeptical of the ‘correct answer’ to reduce extreme modeling around some degree of bad answers. Thus, what label smoothing does is force the neural nets to be less confident in it’s answers by training it to move towards the ‘1-adjustment’ target, and then dividing the adjustment amount over the remaining classes…. rather than simply a hard 1. For our binary dog/cat example, label smoothing of .1 means the target answer would be .90 (90% confident) it’s a dog for a dog image, and .10 (10% confident) it’s a cat, rather than the previous move towards 1 or 0. By being a bit less certain, it acts as a form of regularization and improves it’s ability to perform better on new data. Label smoothing’s affect on Neural Networks: Now we get to the heart of the paper, which shows visually how label smoothing affects the NN’s classification processing. ResNet classifying “airplane, automobile and bird” during training and validation. // small ResNet training for classifying 3 image categories…note the tremendous difference in cluster tightness // small ResNet validation results. Label smoothing increased the final accuracy. Note that while the label smoothing drives activations to tight clusters in training, in validation it spreads around the center and leverages a full range of confidences with it’s predictions.
As the images visually show, label smoothing produces tighter clustering and greater separation between categories for the final activations. This is a primary reason why label smoothing produces more regularized and robust neural networks, that importantly tend to generalize better on future data. However, there’s an additional beneficial effect than just better activation centering.
3. Data Preprocessing
In image classification domain, usually neural networks are extremely tolerant to image geometrical transformation. It is actually encouraged to randomly augment the images e.g. randomly flip, rotate and crop images in order to improve generalization accuracy and avoid overfitting. In terms of types of detection networks, there are two type of pipelines for generalizing final predictions. First is single stage detector networks, where final outputs are generated directly from feature map from the CNN backbone, for example SSD(single shot detector) and YOLO networks. The second type is multi-stage proposal and sampling based approaches, following Fast-RCNN, where a certain number of regions are sampled from a large pool of generated ROIs, where final outputs are generated by applying cropping based techniques to the feature maps from CNN backbone. Since multi-stage networks already applies cropping based techniques, they doesn’t need their input to be augmented with random cropping and many more extensive geometric augmentations. But single stage detectors can reproduce highly appealing results if augmentation is applied to the input images. This is the major difference between one-stage and so called multi-stage object detection data pipelines.
4. Training Schedule Revamping
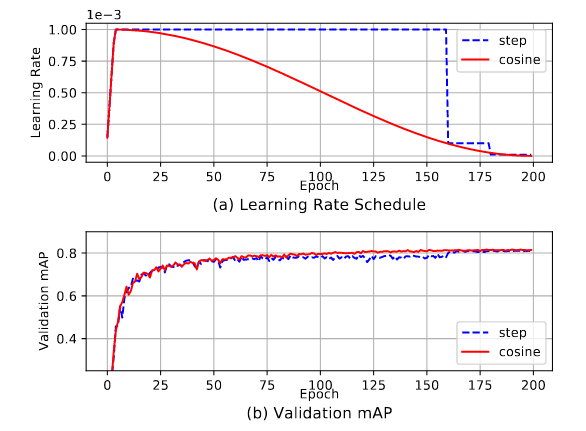
During training, the learning rate usually starts with a relatively big number and gradually becomes smaller throughout the training process. For instance the default learning rate schedule for Faster-RCNN is to reduce learning rate by ratio 0.1 to 60k iterations. Similarly, YOLOv3 uses same ratio 0.1 to reduce learning rate at 40k and 45k iterations. As this is a sharp learning rate transition which may cause the optimizer to re-stabilize the learning momentum in the next few iterations. In contrast a smoother cosine learning rate adjustment can be used. Cosine schedules scales the learning rate according to the value of cosine function on 0 to pi. Visualization of learning rate scheduling with warmup enabled for YOLOv3 training on Pascal VOC. (a): cosine and step schedules for batch size 64. (b): Validation mAP comparison curves using step and cosine learning schedule. Warmup learning rate is another common strategy to avoid gradient explosion during the initial training iterations. Training with cosine schedule and proper warmup lead to better validation accuracy as shown in the figure.
5. Synchronized Batch Normalization and Random Shape Input
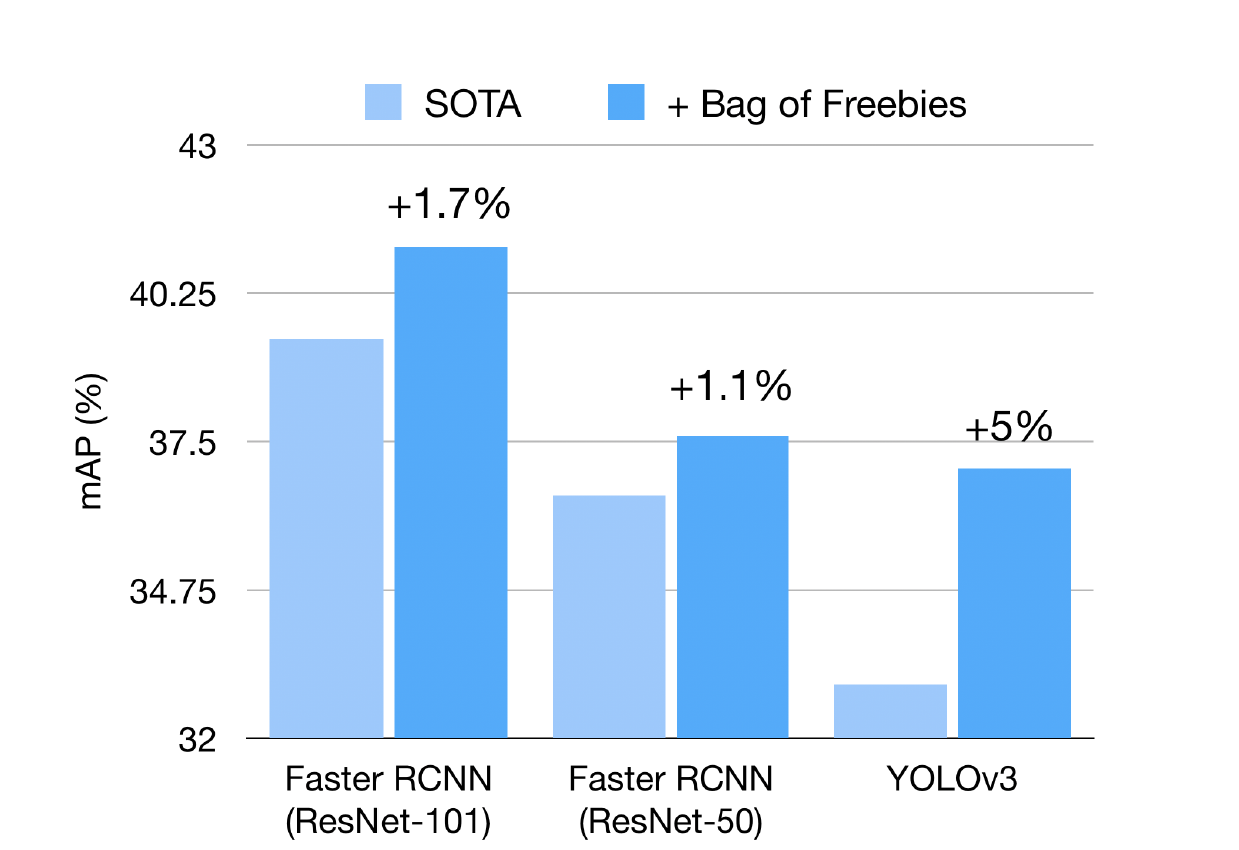
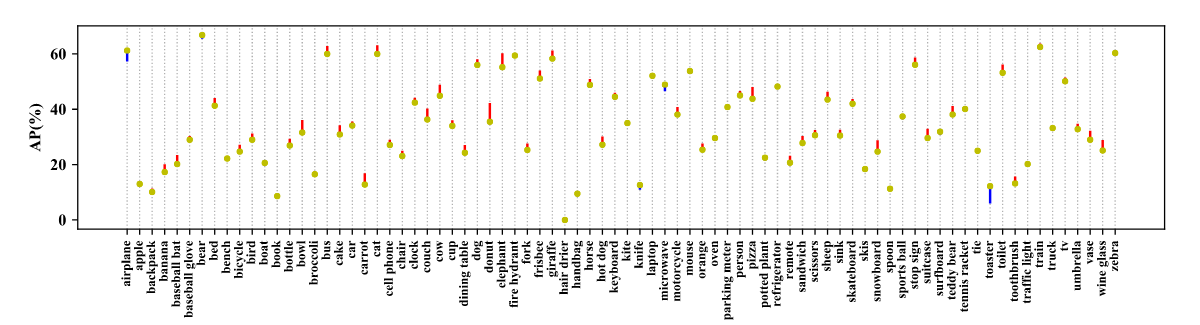
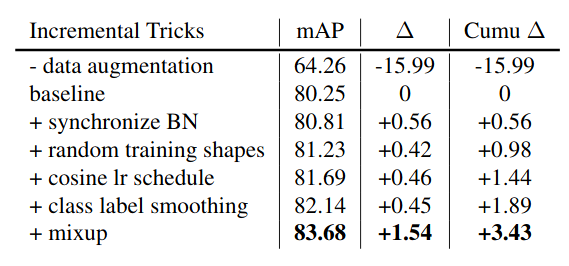
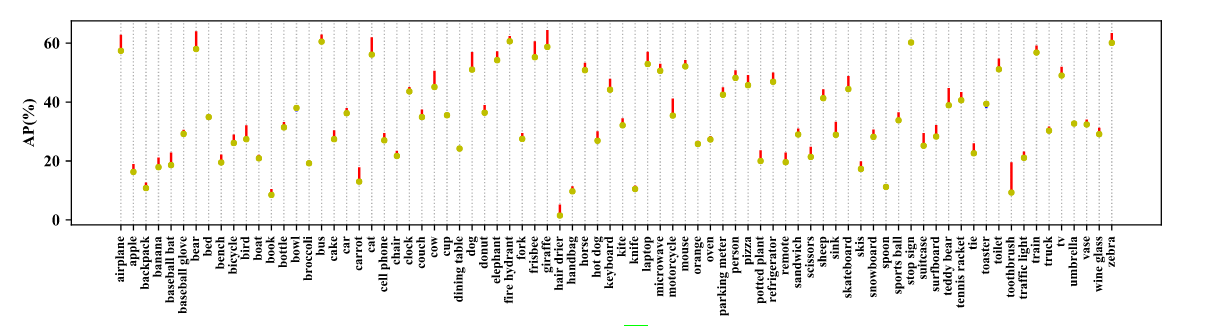
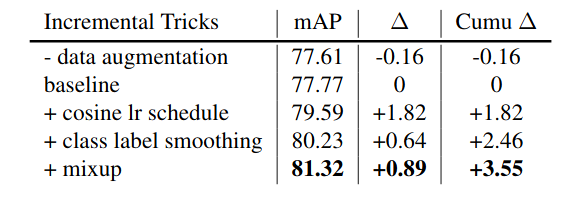
Neural networks are compute intensive but are highly parallelizable. This leads us to the need of computation environments to equip multiple devices (GPUs) to accelerate training. Batch Normalization helps us to train input data in chunks while reducing sensitivity towards hyperparameters. Although the typical implementation of Batch Normalization working on multiple devices (GPUs) is fast, but experiments suggests that reducing size of batch size on multiple devices causing slightly different statistics during computation, which potentially degraded performance. This is not a significant issue in some standard vision tasks such as ImageNet classification (as the batch size per device is usually large enough to obtain good statistics). However, it hurts the performance in some tasks with a small batch size (e.g., 1 per GPU). Natural training images come in various shapes. To fit memory limitation and allow simpler batching, many single-stage object detection networks are trained with fixed shapes. To reduce risk of overfitting and to improve generalization of network prediction, researchers follow YOLOv3’s official implementation details and used a mini-batch of N training images and resized to N x 3 x H x W, where H and W are multipliers of network stride. For example YOLOv3 use H = W = {320,352,384,416,448,480,512,544,576,608} for training using VGG as CNN backbone whose stride is 32. Results Stacking all these tweaks for object detection, researchers sticked to major frameworks YOLOv3(representing single-stage pipelines) which is famous for its efficiency and good accuracy and Faster-RCNN(representing multi-stage pipelines) which is one of the most adopted detection framework and foundation of many others variant. YOLOv3 //small ->COCO 80 category AP analysis with YOLOv3 .Red lines indicate performance gain using bag of freebies, while blue lines indicate performance drop.<- As we can see in the above representation, YOLOv3 is trained on COCO dataset on which have almost 80 categories. while using the above tweaks researchers can claim the performance gain (shown in red) and we can also see some performance drop (shown in blue). But overall YOLOv3 gets 3.43% performance gain on AP. //small Incremental trick validation results of YOLOv3, evaluatedat416×416on Pascal VOC 2007 test set. Faster-RCNN // small COCO 80 category AP analysis with Faster-RCNN resnet50. Red lines indicate performance gain using bag of freebies, while blue lines indicate performance drop. Similarly in the above representation, Faster-RCNN with ResNet50 CNN backbone also trained on COCO dataset. while using the above tweaks researchers can claim the performance gain (shown in red) and we can also see some performance drop (shown in blue). But overall Faster-RCNN gets 3.55% performance gain on AP.
Conclusion In this article, we showed that how bag of training enhancements significantly improves model performances while introducing zero overhead to the inference environment. Empirical experiments of YOLOv3 and Faster-RCNN on Pascal VOC and COCO datasets show that the bag of tricks are consistently improving object detection models. By stacking all these tweaks, we observe no signs of degradation of any level and suggest a wider adoption to future object detection pipelines. These freebies are all training time modifications and therefore only affect model weights without increasing inference time or change of network structures. References [1] Bag of Freebies for Training Object Detection Neural Networks. https://arxiv.org/pdf/1902.04103.pdf [2] YOLOv4: Optimal Speed and Accuracy of Object Detection. https://arxiv.org/pdf/2004.10934.pdf [3] Gluoncv toolkit. https://github.com/dmlc/gluon-cv [4] Redmon and A. Farhadi. Yolov3: An incremental improvement. https://arxiv.org/abs/1804.02767 [5] Label Smoothing & Deep Learning: Google Brain explains why it works and when to use (SOTA tips). https://medium.com/@lessw/label-smoothing-deep-learning-google-brain-explains-why-it-works-and-when-to-use-sota-tips-977733ef020 [6] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. https://arxiv.org/abs/1506.01497
Args: up: ascending if ''up'' is true, and decreasing otherwise. x: A sequence of integers.
Returns: Sorted sequence of integers. """ if len(x) <= 1: return x else: first = bitonic_sort(True, x[:len(x) // 2]) second = bitonic_sort(False, x[len(x) // 2:]) return bitonic_merge(up, first + second)
def bitonic_merge(up: bool, x) -> List[int]: # Assume input x is bitonic, and sorted list is returned if len(x) == 1: return x else: bitonic_compare(up, x) first = bitonic_merge(up, x[:len(x) // 2]) second = bitonic_merge(up, x[len(x) // 2:]) return first + second
def bitonic_compare(up: bool, x) -> None: dist = len(x) // 2 for i in range(dist): if (x[i] > x[i + dist]) == up: x[i], x[i + dist] = x[i + dist], x[i] # Swap
Let`s say if we have an array A[0:11] = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 9] How do we make use parallel computing to do the quick sort here. In order to do a quick sort, we should first find a number as a pivot point. Let take the A[9] = 3 as the pivot point. [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 9] ^ | pivot so we can load each number into a memory cell, and compare all the number with A[9]. We create an array to store the result – if the number if greater than the pivot number, we assign it to 0, otherwise 1.
so we have original array = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 9] A[:] <= pivot ? [1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0] scan the array above we will have:[0, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4]
we can easily get the L[0:4] = [3, 1, 1, 2, 3]
Psedo code:
1. first we compute the flags,
2. do a scan to get the indices
3.
This article will introduce the most basic 5 different multi-threading methods implementation in Python. We will use a very simple example to show how to make use of these 5 different methods to solve a problem.
Barrier
Barrier objects in python are used to wait for a fixed number of thread to complete execution before any particular thread can proceed forward with the execution of the program. Each thread calls wait() function upon reaching the barrier. The barrier is responsible for keeping track of the number of wait() calls. If this number goes beyond the number of threads for which the barrier was initialized with, then the barrier gives a way to the waiting threads to proceed on with the execution. All the threads at this point of execution, are simultaneously released.
There are several main methods available from this object:
parties()
A number of threads required to reach the common barrier point.
n_waiting()
Number of threads waiting in the common barrier point
broken()
A boolean value, True- if the barrier is in the broken state else False. ####wait( timeout = None) Wait until notified or a timeout occurs. If the calling thread has not acquired the lock when this method is called, a runtime error is raised. This method releases the underlying lock and then blocks until it is awakened by a notify() or notify_all() method call for the same condition variable in another thread, or until the optional timeout occurs. Once awakened or timed out, it re-acquires the lock and returns. When the timeout argument is present and not None, it should be a floating point number specifying a timeout for the operation in seconds (or fractions thereof).
reset()
Set or return the barrier to the default state .i.e. empty state. And threads waiting on it will receive the BrokenBarrierError.
bort()
This will put the barrier into a broken state. This causes all the active threads or any future calls to wait() to fail with the BrokenBarrierError. Here is a program to show how barrier works in python
The threading module of Python includes locks as a synchronization tool. A lock has two states: locked and unlocked. A lock can be locked using the acquire() method. Once a thread has acquired the lock, all subsequent attempts to acquire the lock are blocked until it is released. The lock can be released using the release() method.
Calling the release() method on a lock, in an unlocked state, results in an error.
Let us take an example to see how to make use lock to solve a race condition problem.
Race condition is a significant problem in concurrent programming. The condition occurs when one thread tries to modify a shared resource at the same time that another thread is modifying that resource – this leads to garbled output, which is why threads need to be synchronized.
# Importing the threading module import threading # Declraing a lock lock = threading.Lock() deposit = 100 # Function to add profit to the deposit def add_profit(): global deposit for i in range(100000): lock.acquire() deposit = deposit + 10 lock.release() # Function to deduct money from the deposit def pay_bill(): global deposit for i in range(100000): lock.acquire() deposit = deposit - 10 lock.release() # Creating threads thread1 = threading.Thread(target = add_profit, args = ()) thread2 = threading.Thread(target = pay_bill, args = ()) # Starting the threads thread1.start() thread2.start() # Waiting for both the threads to finish executing thread1.join() thread2.join() # Displaying the final value of the deposit print(deposit)
Let us use a list variable to record the whole process how deposit changes alone the way. If we do not have the lock.acquire() and lock.release(), the result may looks like below when there is no lock.acquire() and lock.release() present:
With the usage of lock.acquire() and lock.release(), it will be like:
Semaphore Object
A semaphore manages an internal counter which is decremented by each acquire() call and incremented by each release() call. The counter can never go below zero; when acquire() finds that it is zero, it blocks, waiting until some other thread calls release().
There are several main methods available from this object:
acquire(blocking=True, timeout=None):
release()
Mutex(Lock) VS Semaphore
As we can tell, the methods we have from Lock instance are pretty similar to the methods we have from Semaphore. Then what is the difference between Mutex and Semaphore ?
Mutex is a mutual exclusion object that synchronizes access to a resource. It is created with a unique name at the start of a program. The Mutex is a locking mechanism that makes sure only one thread can acquire the Mutex at a time and enter the critical section. This thread only releases the Mutex when it exits the critical section.
A semaphore is a signalling mechanism and a thread that is waiting on a semaphore can be signaled by another thread. This is different than a mutex as the mutex can be signaled only by the thread that called the wait function.
There are mainly two types of semaphores i.e. counting semaphores and binary semaphores.
Counting Semaphores are integer value semaphores and have an unrestricted value domain. These semaphores are used to coordinate the resource access, where the semaphore count is the number of available resources.
The binary semaphores are like counting semaphores but their value is restricted to 0 and 1. The wait operation only works when the semaphore is 1 and the signal operation succeeds when semaphore is 0.
Event Object
One thread can signal an event and other threads wait for it. There are several main methods available from this object:
isSet()
Return true if and only if the internal flag is true
set()
Set the internal flag to true. All threads waiting for it to become true are awakened. Threads that call wait() once the flag is true will not block at all.
clear()
Reset the internal flag to false. Subsequently, threads calling wait() will block until set() is called to set the internal flag to true again.
wait([timeout in seconds])
Block until the internal flag is true.
Condition
There are several main methods available from this object:
Condition([lock])
If the lock argument is given and not None, it must be a Lock or RLock object, and it is used as the underlying lock. Otherwise, a new RLock object is created and used as the underlying lock.
acquire(*args)
Acquire the underlying lock. This method calls the corresponding method on the underlying lock; the return value is whatever that method returns.
release ()
Release the underlying lock. This method calls the corresponding method on the underlying lock; there is no return value.
wait([timeout])
notify()
Wake up a thread waiting on this condition, if any. This must only be called when the calling thread has acquired the lock.
notifyAll()
Wake up all threads waiting on this condition.
Example
Ok. At the end, let see a problem which can be solved by making use Brutal force, Barrier, Event, Condition, Lock and Semaphore.
Now we have an instance of Foo which will be passed to 3 different threads. Thread A will call first(), thread B will call second(), thread C will call third(). Design a mechanism to ensure that the second() is executed after first(), third() is executed after second().
Brutal Force
We definite can make use of a very brutal force way to solve this problem by setting a flag with in the class. Until the flag was trigger, we are not able to move forward. Refer to the code below:
import time class Foo(object): def __init__(self): self.status = 0
def first(self, printFirst): # printFirst() outputs "first". Do not change or remove this line. while self.status != 0: time.sleep(0.001) printFirst() self.status = 1 def second(self, printSecond): # printSecond() outputs "second". Do not change or remove this line. while self.status != 1: time.sleep(0.001) printSecond() self.status = 2 def third(self, printThird): # printThird() outputs "third". Do not change or remove this line. while self.status != 2: time.sleep(0.001) printThird()
Barrier
Raise two barriers. Both wait for two threads to reach them.
First thread can print before reaching the first barrier. Second thread can print before reaching the second barrier. Third thread can print after the second barrier.
Start with two locked locks. First thread unlocks the first lock that the second thread is waiting on. Second thread unlocks the second lock that the third thread is waiting on.
class Foo: def __init__(self): self.locks = (Lock(),Lock()) self.locks[0].acquire() self.locks[1].acquire() def first(self, printFirst): printFirst() self.locks[0].release() def second(self, printSecond): with self.locks[0]: printSecond() self.locks[1].release() def third(self, printThird): with self.locks[1]: printThird()
Semaphore
Start with two closed gates represented by 0-value semaphores. Second and third thread are waiting behind these gates. When the first thread prints, it opens the gate for the second thread. When the second thread prints, it opens the gate for the third thread.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
from threading import Semaphore class Foo: def __init__(self): self.gates = (Semaphore(0),Semaphore(0)) def first(self, printFirst): printFirst() self.gates[0].release() def second(self, printSecond): with self.gates[0]: printSecond() self.gates[1].release() def third(self, printThird): with self.gates[1]: printThird()
Event
Set events from first and second threads when they are done. Have the second thread wait for first one to set its event. Have the third thread wait on the second thread to raise its event.
Have all three threads attempt to acquire an RLock via Condition. The first thread can always acquire a lock, while the other two have to wait for the order to be set to the right value. First thread sets the order after printing which signals for the second thread to run. Second thread does the same for the third.
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
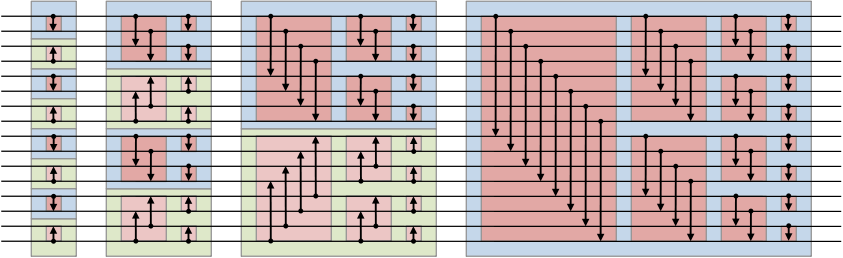
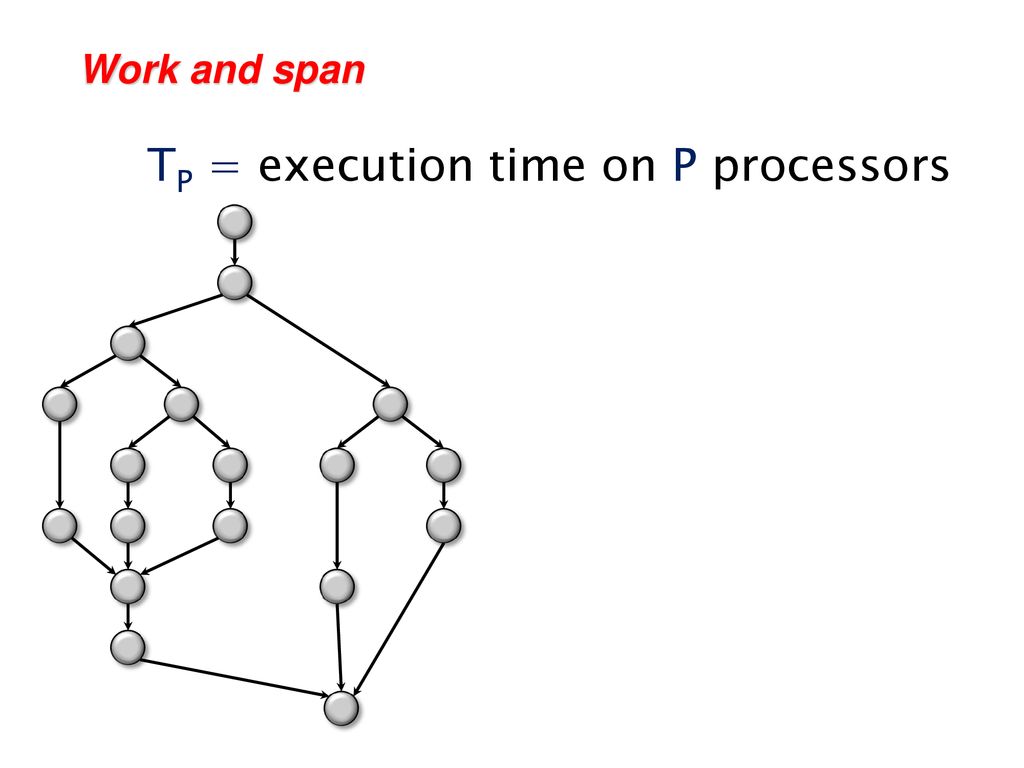
In order to understand how parallel computing works, we have to understand a few concepts. A multithreaded computation can be represetned by a Directed Acyclic Graph of vertices. Each vertex represents the executtion of an instruction. First of all, let`s take a look at 2 concepts: Cost model: Work and Span:
Work
The total work that will be executed by all the processors. If we consider the whole process that a computer finish all the tasks as a Directed Acyclic Graph, then work is the total number of all vertices of the DAG.
Span: sometime we call it depth, is the length of the longest path of the DAG(critical path).
See the picture below, work == 21, span == 8
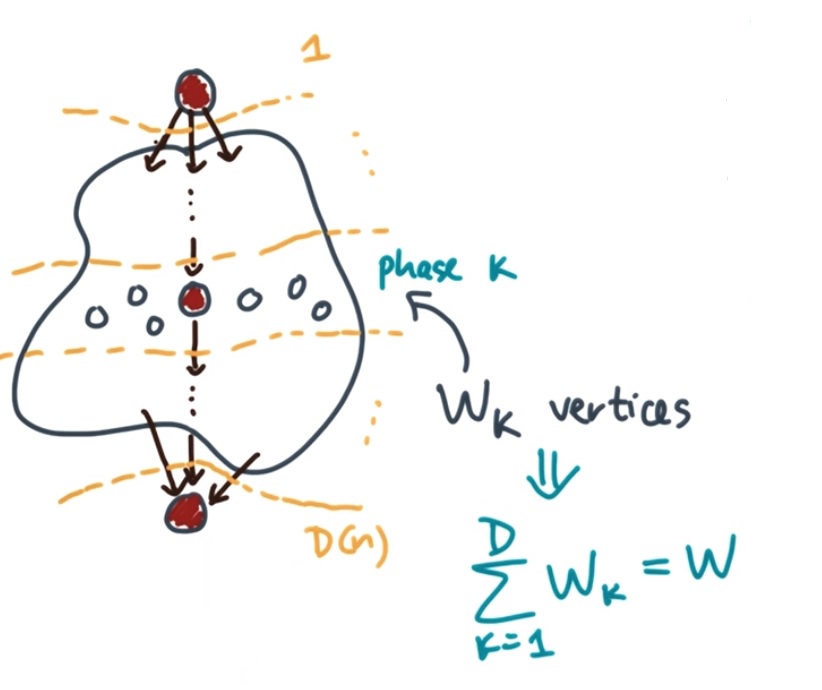
Brent`s Theorem: Brent`s theorem is the theorem to give the upper bound and lower bound of the time that expires between the start of the computation and its end. Let us denote it as Tp, denote total work as W, Span as D, number of processors as N.
Then we can easily have: Tp = ∑(1 to D)(floor(Wi-1)/P) + 1 based on the properties of ceiling and floor operation, we have max(D, ceiling(W/N)) <= Tp <= (W-D)/N + D
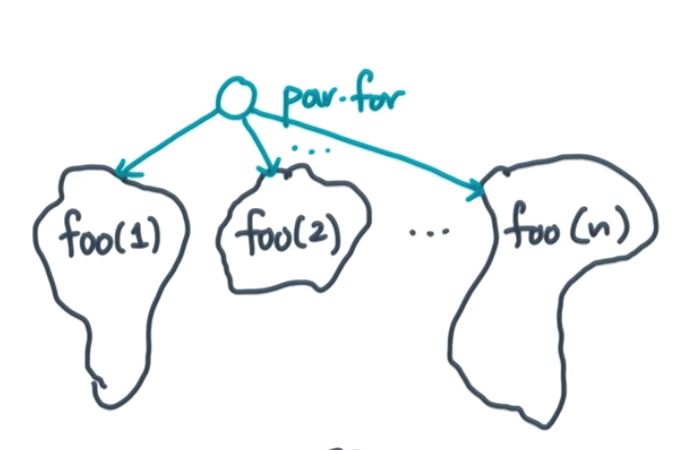
par-for loop: (parallel for loop, sometimes people call it for-any loop or for-all loop) All iterations are independent to each other.
The DAG above shows how does a offline scheduling problem works. In reality, we might don`t have full knowledge of the DAG. Instead, the DAG unfolds as we run the program. Futhermore, we are interested in not only minimizing the length of the schedule but also the work and time it takes to compute the schedule. These 2 conditions defin the online scheduling problem.